
Insights:
A knowledge base is a representation of factual knowledge which characteristically suffer from incompleteness, in the form of missing edges. The goal is to develop a model that assigns a high likelihood to ("MIT", "located in", "Massachusetts") but a low likelihood of ("MIT", "located in", "Belize"), a model that recognizes that some facts hold purely because of other relations in the KB.
Socher introduces "Neural Tensor Networks" which differ from regular neural networks due to the way they relate entities directly to one another with the bilinear tensor product, which is the core operation in a Neural Tensor Network.
The Architecture of this project follows in mainly in three stages firstly the Entity Representation then the Neural Tensor Network and finally Training the model
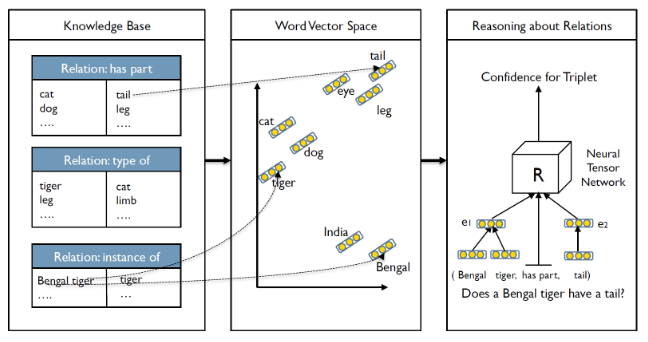
One of the insights from this paper is that entities can be represented as some function of their constituent words, which provides for the sharing of statistical strength between similar entities. For example, "African Elephant" and "Asian Elephant" might have much in common, but previous approaches oftentimes embedded each of these separately. We embed each word ("African", "Asian", and "Elephant") and then build representations for entities as the average of those entities' constituent word vectors.
Word embedding vectors may be initialized randomly, but the model benefits strongly from using pre-trained word embeddings (e.g. by word2vec) which already have some structure built into them. However, once we have vectors representing words, we pass gradients back to them, meaning that those embeddings are by no means static, or final.
Implementation:
The goal of our approach is to be able to state whether two entities (e1 , e2 ) are in a certain relationship R. For instance, whether the relationship (e1 , R, e2 ) = (Bengal tiger, has part, tail ) is true and with what certainty. To this end, we define a set of parameters indexed by R for each relation’s scoring function. Let e1 , e2 ∈ R be the vector representations (or features) of the two entities. For now we can assume that each value of this vector is randomly initialized to a small uniformly random number.
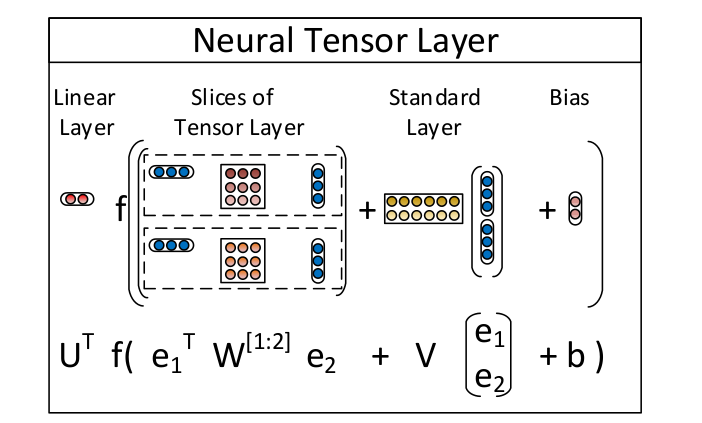
The NTN replaces a standard linear neural network layer with a bilinear tensor layer that directly relates the two entity vectors across multiple dimensions. The model computes a score of how likely it is that two entities are in a certain relationship by the following NTN-based function:
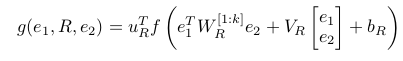
The visualization of the above equation can be seen as:
- All models are trained with contrastive max-margin objective functions. The main idea is that each triplet in the training set
Ti = (ei1, Ri, ei2 ) should receive a higher score than a triplet in which one of the entities is replaced with a random entity. - Each relation has its associated neural tensor net parameters. We call the corrupted triplet as Tci = (ei1 , Ri , ec ), where we sampled entity ec randomly from the set of all entities that can appear at that position in that relation.
We minimize the following objective function:
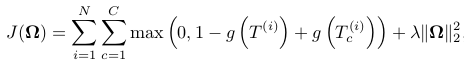
where N is the number of training triplets and we score the correct relation triplet higher than its corrupted one up to a margin of 1.- We use mini-batched L-BFGS for optimization which converges to a local optimum of our non-convex objective functionposition in that relation.
- Experiments are conducted on both WordNet and FreeBase to predict whether some relations hold using other facts in the database. Our goal is to predict correct facts in the form of relations (e1 , R, e2 ) in the testing data. This could be seen as answering questions such as Does a dog have a tail?, using the scores g(dog, has part, tail) computed by the various models.
- We use the development set to find a threshold TR for each relation such that if g(e1 , R, e2 ) ≥ TR , the relation (e1 , R, e2 ) holds, otherwise it does not hold.
- The final accuracy is based on how many triplets are classified correctly.
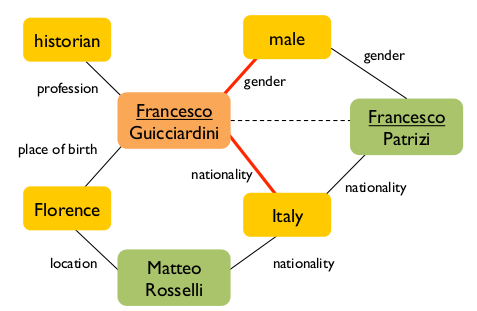
Image on the right is a reasoning example in FreeBase where black lines denote relationships in training, red lines denote relationships the model inferred. The dashed line denotes word vector sharing.
Results:
Accuracy for NTN model on Freebase Database
Using learned word embeddings

Using Random word embeddings

Accuracy for NTN model on WordNet Database
Using learned word embeddings

Using Random word embeddings

Model Comparisons for the 2 databases:

Conclusions
- We introduced Neural Tensor Networks for knowledge base completion. Unlike previous models for predicting relationships using entities in knowledge bases, our model allows mediated interaction of entity vectors via a tensor. The model obtains the highest accuracy in terms of predicting unseen relationships between entities through reasoning inside a given knowledge base. It enables the extension of databases even without external textual resources.
- We further show that by representing entities through their constituent words and initializing these word representations using readily available word vectors, performance of all models improves substantially
- The project has many applications in Information Retrieval and Extraction some of which are:
- Link Prediction
- Semantic Parsing
- Question Answering
- Knowledge Base Expansion
- Named Entity Recognition
About Project:
This is the major project of course Information Reterival and Extraction. The project was done in the team of three members at International Institute of Information Technology - Hyderabad under the guidance of Ganesh Jawahar
Contributers:
- Shubham Agarwal, IIIT Hyderabad.
- Darshan Jaju, IIIT Hyderabad.
- Surbhi Gupta, IIIT Hyderabad.